Research
I am interested in emergence, AI, and physics. My current focus is on 1) (empirical) theories of deep learning & deep learning understanding, and 2) applying deep learning methods to the physical sciences, especially astrophysics and quantum. I’m especially keen on neural network scaling & its benefits.
|
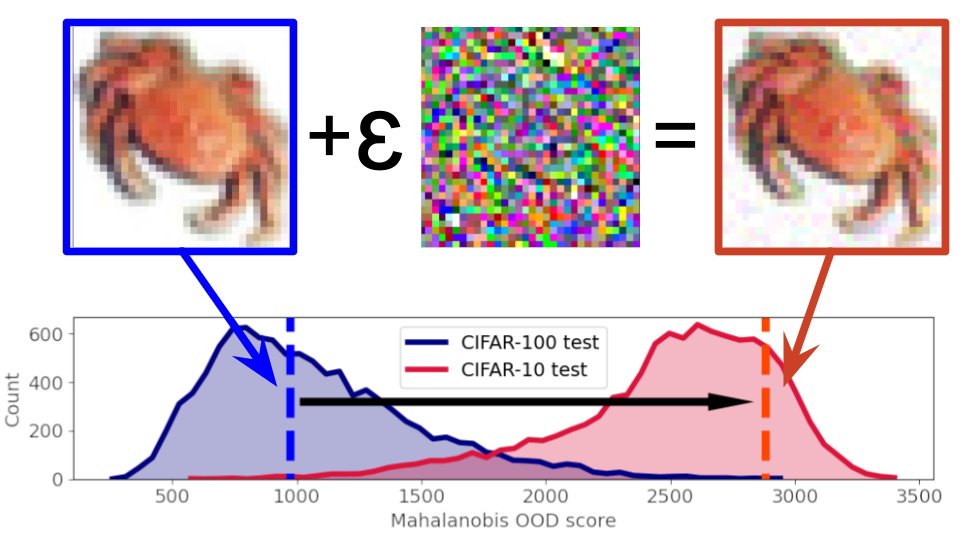
Large models and massive pretraining have significantly improved near-OOD detection. Despite that, we show that even the most well-performing methods are very brittle when we design adversarial attacks specifically against their OOD score. The code is available on GitHub. |
|
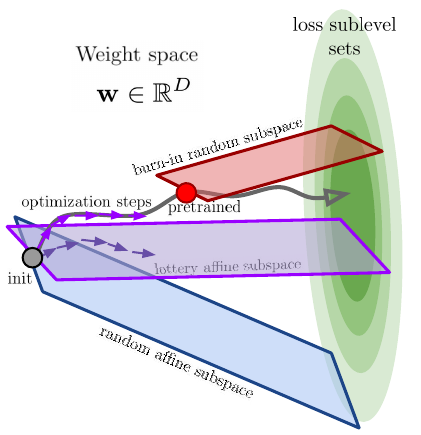
Deep neural networks are capable of training and generalizing well in many low-dimensional manifolds in their weights. We explain this phenomenon by first examining the success probability of hitting a training loss sublevel set when training within a random subspace of a given training dimensionality using Gordon's escape theorem. |
|
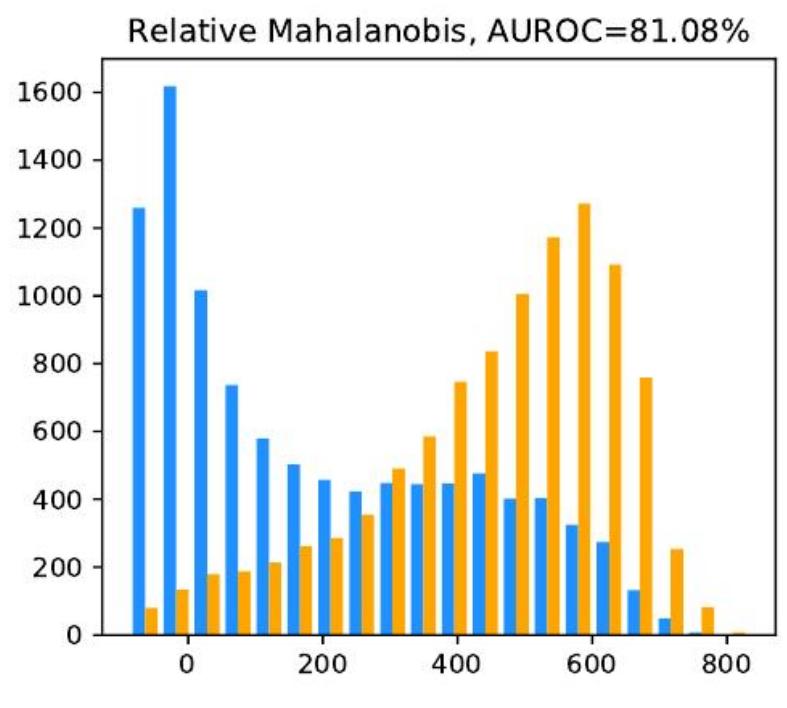
We analyze the failure modes of the Mahalanobis distance method for near-OOD detection and propose a simple fix called relative Mahalanobis distance (RMD) which improves performance and is more robust to hyperparameter choice. Accepted at the Uncertainty & Robustness in Deep Learning workshop at ICML 2021. |
|
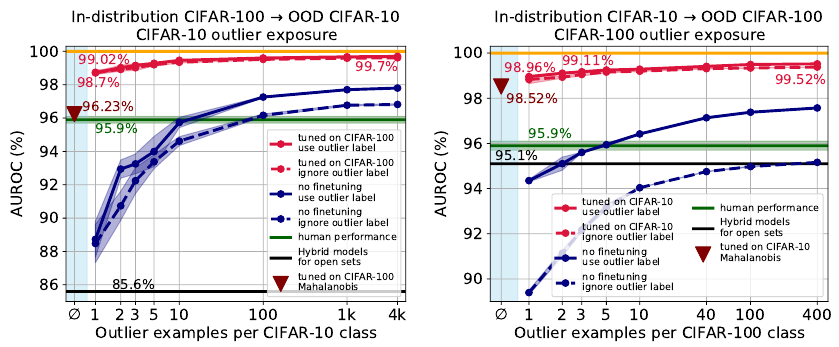
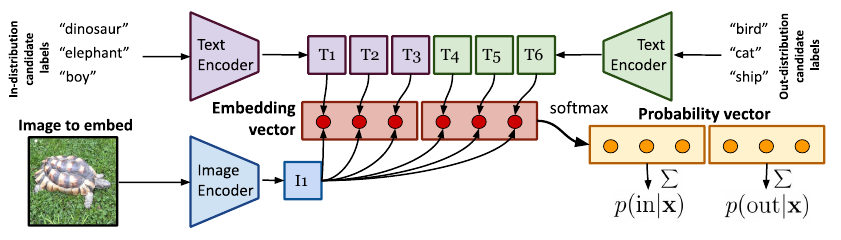
We improve the AUROC from 85% (current SOTA) to more than 96% using Vision Transformers pre-trained on ImageNet-21k. On a challenging genomics OOD detection benchmark, we improve the AUROC from 66% to 77% using transformers and unsupervised pre-training. For multi-modal image-text pre-trained transformers such as CLIP, we explore a new way of using just the names of outlier classes as a sole source of information without any accompanying images. Accepted at the Uncertainty & Robustness in Deep Learning workshop at ICML 2021. |
|
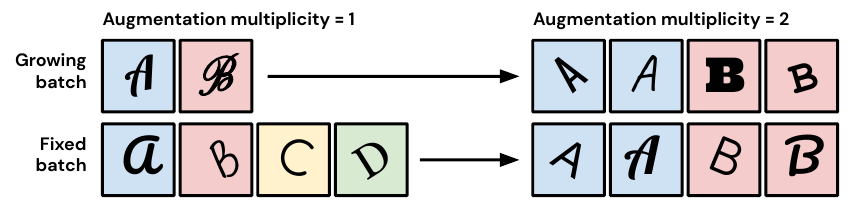
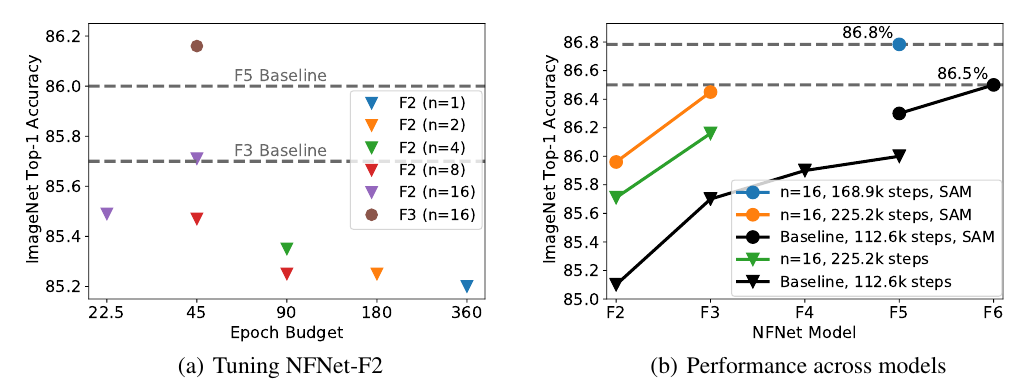
By applying augmentation multiplicity to the recently proposed NFNet model family, we achieve a new ImageNet SotA of 86.8% top-1 accuracy without extra data after just 34 epochs of training with an NFNet-F5 using the SAM optimizer. |
|
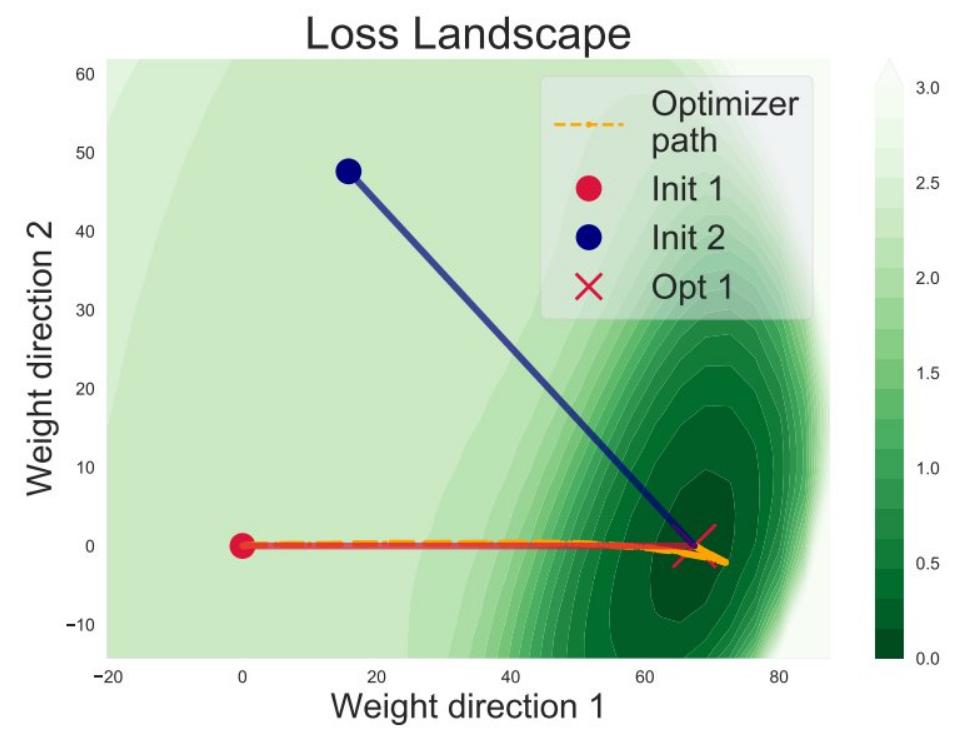
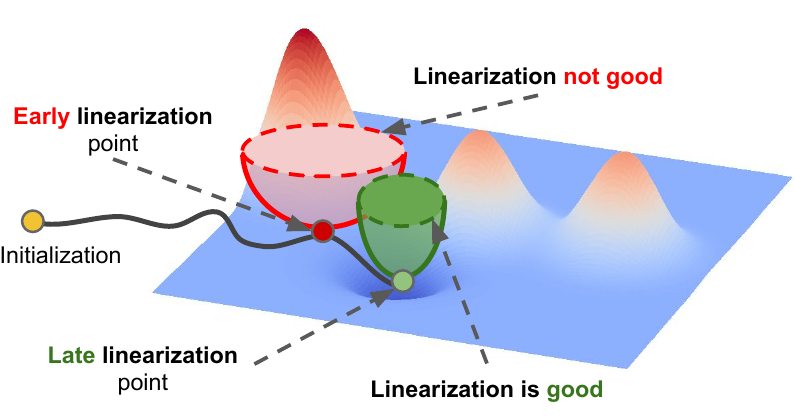
Linear interpolation from initial to final neural net params typically decreases the loss monotonically. We investigate this phenomenon empirically and theoretically. |
|
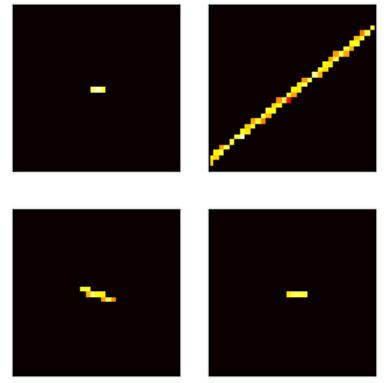
Using machine learning algorithms for identification of background (noise) charge particles in X-ray imaging detectors, with a particular emphasis on the proposed Athena X-ray observatory's WFI science products module. Accepted for publication at Proceedings of the SPIE, Astronomical Telescopes and Instrumentation, Space Telescopes and Instrumentation 2020: Ultraviolet to Gamma Ray. |
|
We study the relationship between the training dynamics of nonlinear deep networks, the geometry of the loss landscape, and the time evolution of a data-dependent NTK. We do so through a large-scale phenomenological analysis of training, synthesizing diverse measures characterizing loss landscape geometry and NTK dynamics. Accepted for publication at NeurIPS 2020 in Vancouver as a poster. |
|
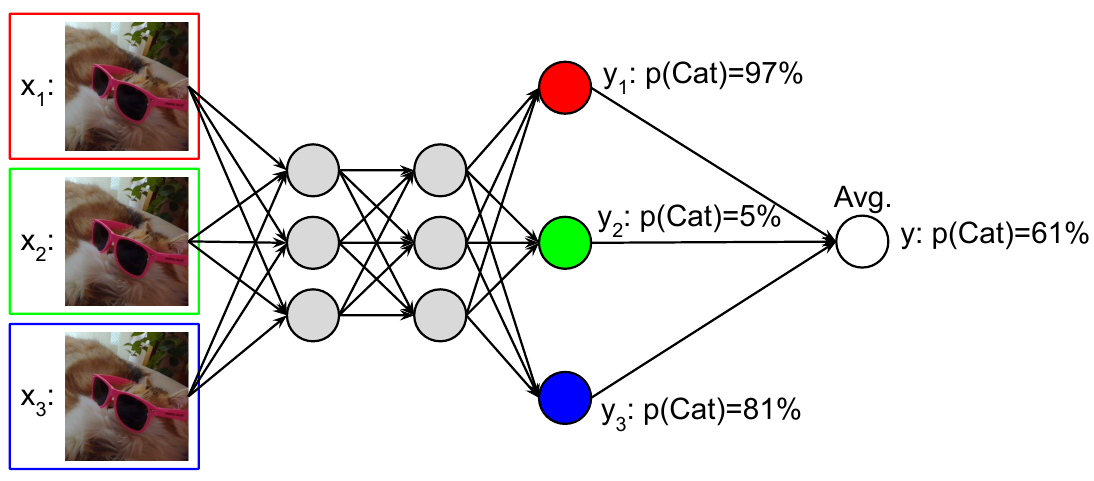
Using a multi-input multi-output (MIMO) configuration, we can utilize a single model's capacity to train multiple subnetworks that independently learn the task at hand. |
|
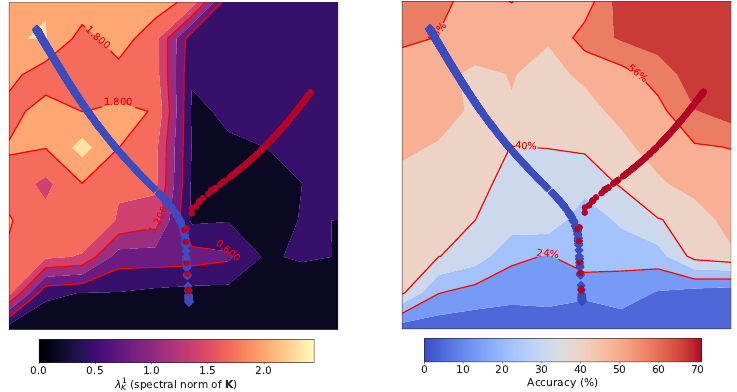
In the early phase of training of deep neural networks there exists a "break-even point" which determines properties of the entire optimization trajectory. Accepted as a spotlight talk at the International Conference on Learning Representations 2020 (ICLR) in Addis Ababa, Ethiopia. |
|
Exploring the consequences of the neural network loss landscape structure for ensembling, Bayesian methods, and calibration. Accepted as a contributed talk at Bayesian Deep Learning workshop at NeurIPS 2019 in Vancouver. |
|
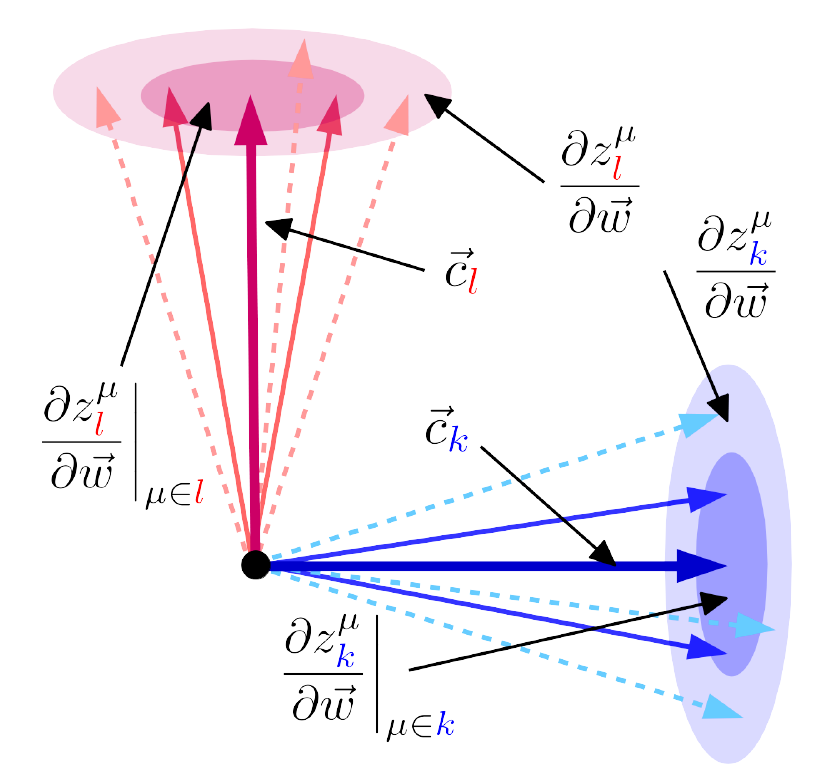
By modelling logit gradient clustering and the effect of training as logit scale growth, we constructed a simple analytical model of the gradient and Hessian of neural networks in classification problems. From this minimal model, we successfully recovered 4 previously observed surprising empirical phenomena related to the local stucture of neural network loss landscapes, demonstrating that their origin is likely very generic in nature and not specific to the natural data distributions, neural networks, or gradient descent, as previously conjectured. |
|
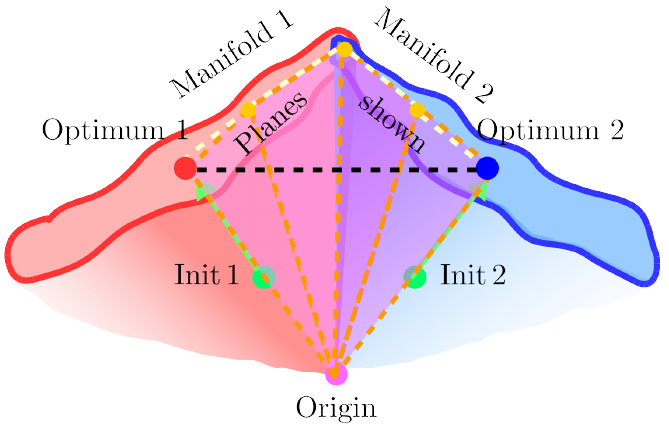
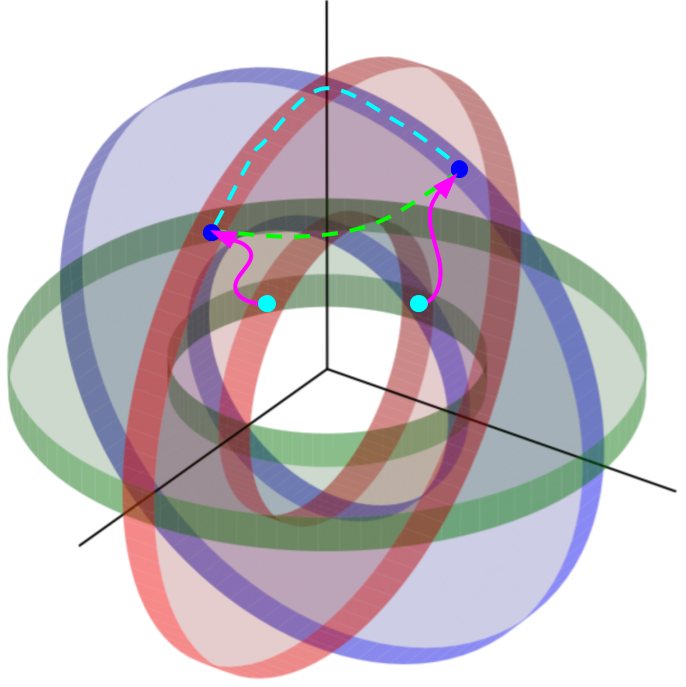
Building a unified phenomenological model of the low-loss manifold in neural network loss landscapes that incorporates 1) mode connectivity, 2) the surprising ease of optimizing on low-dimensional cuts through the weight space, and 3) the existence of long directions in the loss landscape into a single model. Using this model, we made new predictions about the loss landscape and verified them empirically. Accepted for publication at NeurIPS 2019 in Vancouver as a poster. A subset accepted at the Understanding and Improving Generalization in Deep Learning workshop at ICML 2019 as a spotlight talk and a poster, and at the Theoretical Physics for Deep Learning workshop at ICML 2019 as a poster. I also delivered invited talks at Uber AI Labs and Google Brain. |

|
We defined the concept of stiffness, showed its utility in providing a perspective to better understand generalization in neural networks, observed its variation with learning rate, and defined the concept of dynamical critical length using it. |

|
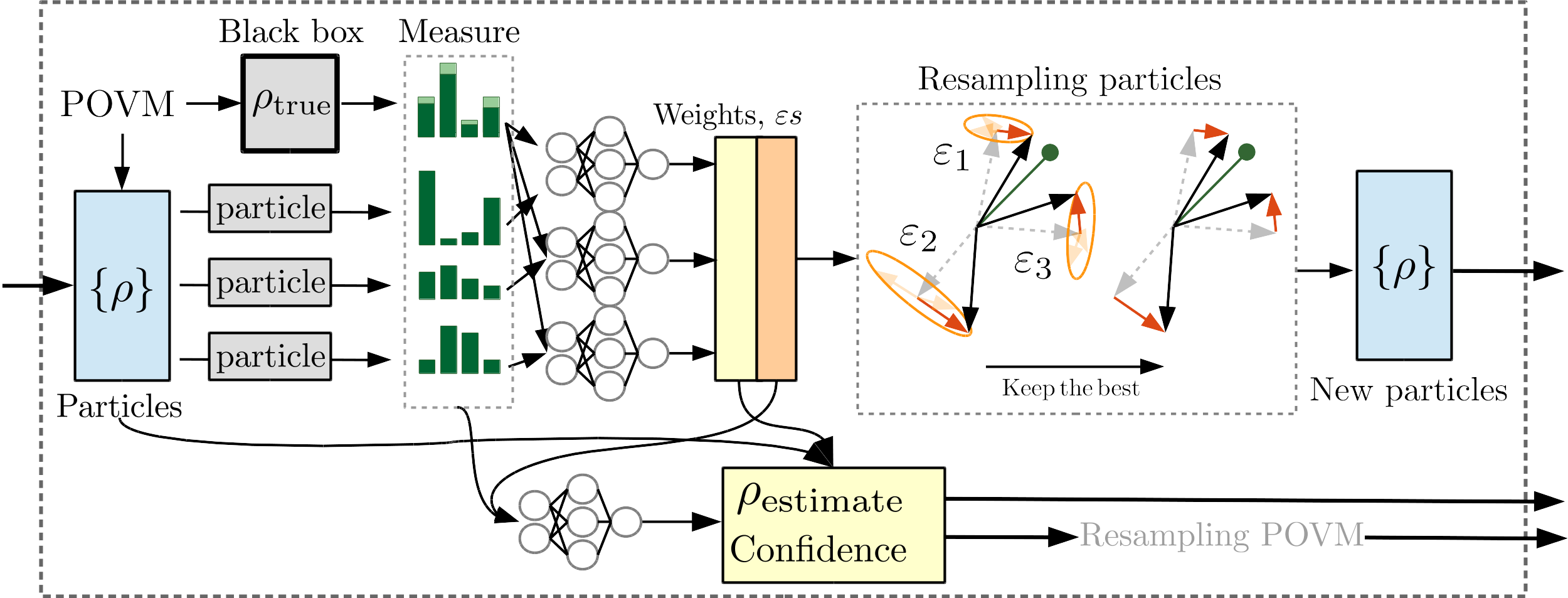
Learning to learn about quantum states using neural networks, swarm optimization and particle filters. We develop a new algorithm for quantum state tomography that learns to perform the state reconstruction directly from data and achieves orders of magnitude computational speedup while retaining state-of-the-art reconstruction accuracy. A subset accepted at the 4th Seefeld Workshop on Quantum Information, 22nd Annual Conference on Quantum Information Processing (QIP 2019) as a poster, 3rd Quantum Techniques in Machine Learning 2019 (QTML) in Korea as a talk, and McGill Physics-AI conference in Montreal as a talk. |
|
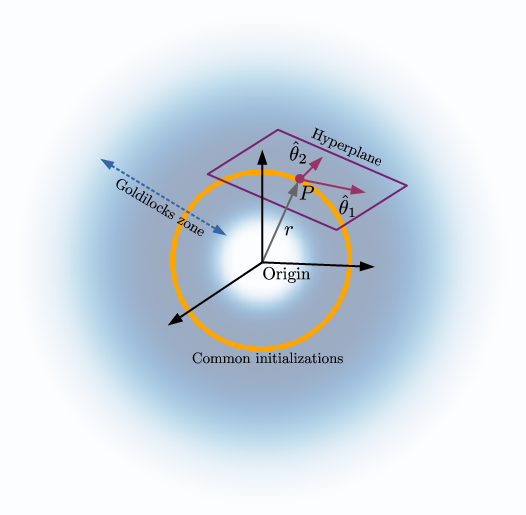
A connection between optimization on random low-dimensional hypersurfaces and local convexity in the neural network loss landscape. Accepted for publication at AAAI 2019 in Hawaii as an oral presentation and a poster. A subset accepted at the Modern Trends in Nonconvex Optimization for Machine Learning workshop at ICML 2018 and BayLearn 2018 as The Goldilocks zone: Empirical exploration of the structure of the neural network loss landscapes (link here). Accepted as an oral presentation at the Theoretical Physics for Machine Learning Aspen winter conference. |

|
A paper on the proposed Athena X-ray observatory's WFI science products module. My part involved exploring the use of AI techniques on board. Published at the Proceedings Volume 10699, Space Telescopes and Instrumentation 2018: Ultraviolet to Gamma Ray. |

|
A novel approach to detection of X-ray cavities in clusters of galaxies using convolutional neural architectures. Accepted at the Deep Learning for Physical Sciences workshop at NIPS 2017. |
|
An architecture capable of dealing with uncertainties for few-shot learning on the Omniglot dataset. Accepted and presented at BayLearn 2017. Essential code available on GitHub. </td> </tr> |
|
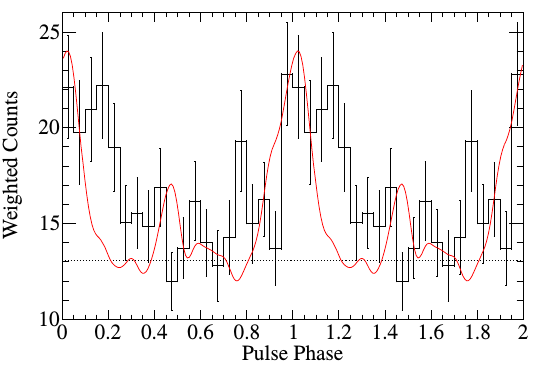
A pulsar detection in gamma-ray. |