Solving adversarial attacks in computer vision as a baby version of general AI alignment
Stanislav Fort (Twitter, website, and Google Scholar)
I spent the last few months trying to tackle the problem of adversarial attacks in computer vision from the ground up. The results of this effort are written up in our new paper Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness (explainer on X/Twitter). Taking inspiration from biology, we reached state-of-the-art or above state-of-the-art robustness at 100x – 1000x less compute, got human-understandable interpretability for free, turned classifiers into generators, and designed transferable adversarial attacks on closed-source (v)LLMs such as GPT-4 or Claude 3. I strongly believe that there is a compelling case for devoting serious attention to solving the problem of adversarial robustness in computer vision, and I try to draw an analogy to the alignment of general AI systems here.
1. Introduction
In this post, I argue that the problem of adversarial attacks in computer vision is in many ways analogous to the larger task of general AI alignment. In both cases, we are trying to faithfully convey an implicit function locked within the human brain to a machine, and we do so extremely successfully on average. Under static evaluations, the human and machine functions match up exceptionally well. However, as is typical in high-dimensional spaces, some phenomena can be relatively rare and basically impossible to find by chance, yet ubiquitous in their absolute count. This is the case for adversarial attacks – imperceptible modifications to images that completely fool computer vision systems and yet have virtually no effect on humans. Their existence highlights a crucial and catastrophic mismatch between the implicit human vision function and the function learned by machines – a mismatch that can be exploited in a dynamic evaluation by an active, malicious agent. Such failure modes will likely be present in more general AI systems, and our inability to remedy them even in the more restricted vision context (yet) does not bode well for the broader alignment project. This is a call to action to solve the problem of adversarial vision attacks – a stepping stone on the path to aligning general AI systems.
2. Communicating implicit human functions to machines
The basic goal of computer vision can be viewed as trying to endow a machine with the same vision capabilities a human has. A human carries, locked inside their skull, an implicit vision function mapping visual inputs into semantically meaningful symbols, e.g. a picture of a tortoise into a semantic label tortoise. This function is represented implicitly and while we are extremely good at using it, we do not have direct, conscious access to its inner workings and therefore cannot communicate it to others easily.
To convey this function to a machine, we usually form a dataset of fixed images and their associated labels. We then use a general enough class of functions, typically deep neural networks, and a gradient-based learning algorithm together with backpropagation to teach the machine how to correlate images with their semantic content, e.g. how to assign a label parrot to a picture of a parrot. This process is extremely successful in communicating the implicit human vision function to the computer, and the implicit human and explicit, learned machine functions agree to a large extent.
The agreement between the two is striking. Given how different the architectures are (a simulated graph-like function doing a single forward pass vs the wet protein brain of a mammal running continuous inference), how different the learning algorithms are (gradient descent with backpropagation vs something completely different but still unknown), and how different the actual source of data is (static images and their associated labels vs a video stream from two eyes in an active, agentic setting, exploring an environment), it is a miracle that we end up teaching computers such a well-matching function.
Their agreement on the training set, which is the basic requirement and should surprise no one, generalizes to the test set, i.e. different images drawn from the same semantic classes. Even under large amounts of noise, the human and machine functions still agree, showing a remarkable amount of robustness to perturbations drawn at random. Until a few years ago, humans still enjoyed a large advantage in being able to express uncertainty and not to overreact to images from outside the training distribution. Recently, however, even this gap has closed, primarily due to scaling. All in all, almost everything is getting better and more robust.
All of these examples are a great demonstration that the implicit human function and the explicit machine functions are to a very large extent in agreement with each other. Scaling (of data, compute, and network sizes) has directly led to gains in essentially all good things associated with vision models, from accuracy to robustness, and uncertainty handling. This looks like a monotonic gain in the agreement between humans and computers, suggesting that a path to victory might lead through scaling alone.
3. Extremely rare yet omnipresent failure modes
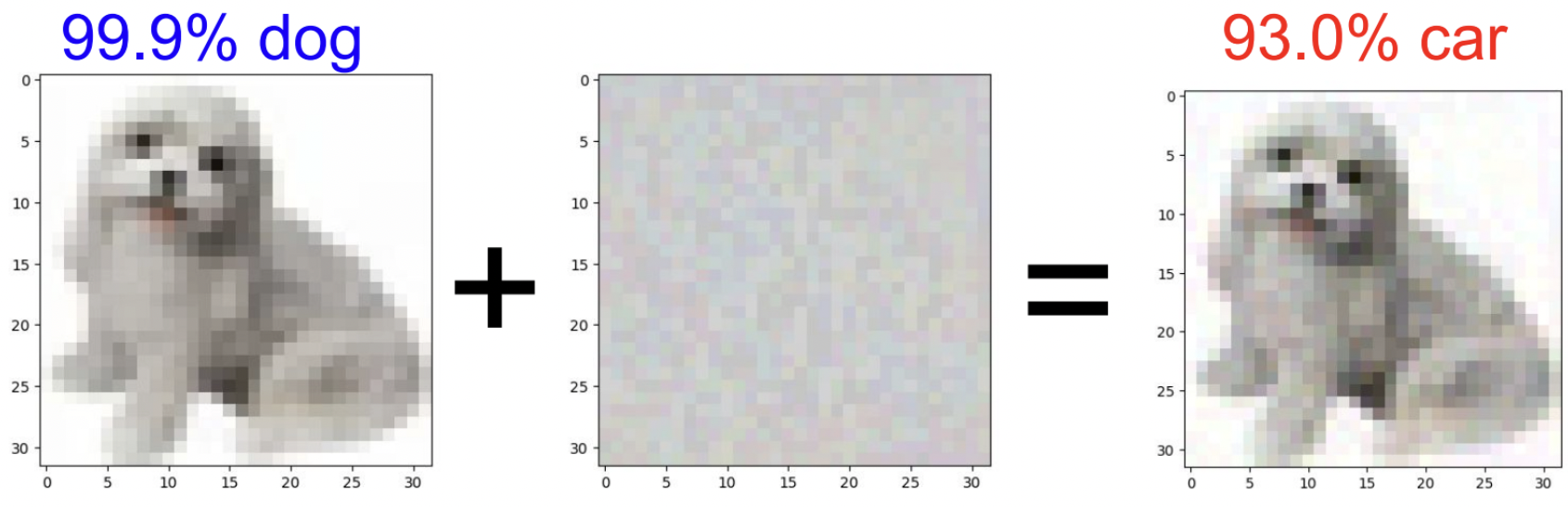
This is, sadly, only a part of the story. In high-dimensional spaces, it is very easy for things to be both 1) statistically extremely rare (= their relative frequency is vanishingly low), yet 2) also very common (= their actual count is high). A decade ago, two papers by a now-very-prolific group of authors (Intriguing properties of neural networks by Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus, and Explaining and Harnessing Adversarial Examples by Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy) identified a very striking empirical phenomenon. A neural network can very easily be fooled into misclassifying an image as something completely different if we just add a very weak but carefully crafted noise to the input image. This has come to be known as adversarial attacks and has been observed everywhere, from classification to out-of-distribution detection, from tiny toy models to state-of-the-art vision systems.
Adversarial attacks are a glaring demonstration of the stark misalignment between the implicit human vision function and whatever has been learned by the machine. A small perturbation that leaves the image completely semantically undisturbed from the human point of view has a catastrophic impact on the machine model, completely impairing its ability to see the ground truth class in it. Apart from image misclassification, we can easily design attacks towards any target class and essentially to any level of confidence. For example, an original image labeled as an 80% tortoise can be misclassified as a 99.999% tank, turning from a decently confident tortoise to the most tank-like tank the model has ever had the pleasure of witnessing!
One of the most striking things about adversarial attacks is that they generalize between machine models. A picture of a cat attacked to look like a car to one vision model will, to a large extent, also look like a car to a completely different vision model, while staying just a cat to a human observer. This demonstrates convincingly that we are dealing with two fundamentally different approaches to vision, that, despite their great typical agreement, have many catastrophic points of divergence.
The cases where the human and machine functions agree are all covered by what can be seen as static evaluations. Some data is presented and the results are checked. Such approaches to evaluations are very common but are limited to studying typical behaviors, and since atypical behaviors in high-dimensional settings can be both impossible to uncover by chance but also extremely frequent and easy to find if we’re explicitly seeking them out, such failure modes can be exploited by motivated, active attackers. In a way, this can be seen as an analogue to deceptive alignment in the broader AI safety context. This regime would have to be covered by a dynamic evaluation which is in a way much more akin to red-teaming than traditional, static benchmarks.
4. Brute force enumerative safety is not sufficient
The usual approach to instilling adversarial robustness in a brittle vision model is called adversarial training. It is extremely brute-force, unscalable, and reliant on enumerating adversarially attacked images. By repeatedly finding them, adding them to the training set with their human-apparent label, and retraining the model to classify them correctly, we are effectively removing the mistaken classifications one by one. The sheer richness of the space of possible images and its partitioning into classes (see e.g. Multi-attacks: Many images + the same adversarial attack → many target labels), however, means that a method that effectively relies on the enumeration of bad behaviors will not be able to scale to realistic scenarios (in vision this means higher resolution images and more classes). Adversarial training is essentially manually patching the space of possibilities by hand. To follow the parallel with AI alignment, enumerative approaches to AI safety have so far produced only superficial guardrails that are routinely jailbroken by users, a situation strictly worse than in vision, where at least some robustness against white-box (i.e. with the attacker’s detailed access to the internals of the model they are trying to break), multi-step, adaptive attacks is the norm (though reached via expensive, brute-force methods).
Despite my fundamental belief that machines can (eventually) do anything, the human brain seems to have some particularly great solutions to many challenging problems, especially where robustness extending to very rarified, long tails is needed (such as self-driving and robust vision). We can take inspiration from that! In vision in particular, I believe that we do something fundamentally different and better, which results in humans not suffering from adversarial attacks the way machines do (there is some evidence of transfer for extremely brief exposure to adversarial images, on the order of 40-60 ms, see Adversarial Examples that Fool both Computer Vision and Time-Limited Humans). By this, I mean that a picture of e.g. a cat would not be misclassified as e.g. a rocket by adding any small modification to it. Some have argued that if we had white-box access to the human brain and visual systems in the same way we have to machine models (i.e. if we could take partial derivatives of the semantic label in the brain with respect to the input visual scene), we could craft such perturbations. I disagree – I think that no such perturbations exist in general, rather than that we have simply not had any luck finding them.
5. Conclusion
The problem of adversarial attacks in vision has a very similar form to the grand challenge of aligning powerful AI systems. We are trying to convey an implicit function firmly locked in the brains of humans to machines via relatively ad-hoc means and without any strict mathematical guarantees. In the case of vision, we would like machine models to see the content of images the same way humans do – to agree on what semantically meaningful symbols are present in them. In the case of general AI systems, we’re trying to communicate human values, behaviors, and implicit preferences in a similarly crude manner.
Both setups involve high-dimensional spaces with their usual trickery – some behaviors can be at the same time essentially non-existent in terms of their typicality, yet very numerous and easy to find if one seeks them out. In both cases, this poses a difficult challenge for static evaluations that effectively verify that the function conveyed matches the human one on average. Yet rare but ubiquitous points of catastrophic mismatch exist, as very concretely demonstrated by the existence of adversarial attacks on vision systems. Analogous failure modes will likely exist for general AIs as well and will be equivalently hard to handle. Scaling alone, as exemplified by brute force adversarial training in vision, can only give a semblance of robustness, however, due to the sheer richness of the space it is effectively training to patch by enumerating failure modes one by one. This is very similar to how enumerative ad-hoc safety solutions in general AI systems provide only weak guardrails, routinely jailbroken by motivated users.
I believe that the problem of adversarial attacks in vision shares many of the key characteristics of the general AI alignment problem. It is also significantly more constrained, and likely much easier to solve. We have well-established benchmarks for it, making it a prime target for concerted safety efforts. Given the similar shape of the problem, it simply has to be solved along the way to AI alignment. Nicholas Carlini, a prolific adversarial attacks researcher, said at ICML 2024 in an AI safety workshop the following:
“In adversarial machine learning we wrote over 9000 papers in ten years and got nowhere. You all have a harder problem. And less time.”
We should dedicate a considerable effort to understanding and solving adversarial attacks in vision. I started myself with the paper Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness (explainer on X/Twitter), taking inspiration from biology and reaching SOTA or above SOTA robustness without any adversarial training at 100x – 1000x less compute. We can view the problem as a proving ground for ideas and techniques to be later applied to the AI alignment problem at large. I believe we can make a dent in it relatively quickly, but it has to be done anyway, so let’s give it a serious try!
If you find this blogpost useful and would like to cite it, please use the following BibTeX:
@misc{
Fort2024AdversarialattacksAIalignment,
title={Solving adversarial attacks in computer vision as a baby version of general AI alignment},
url={https://stanislavfort.com/blog/Adversarial_attacks_and_AI_alignment/},
author={Stanislav Fort},
year={2024},
month={Aug}
}